社内文書を検索して答えるAIアシスタントや、複数の手順を自律的にこなすAIエージェント。その裏側で広く使われているのが「RAG(検索拡張生成)」です。この仕組みに対し、攻撃者がシステムに一切ログインせず、外部から検索されうる文書を数点置くだけでAIの推論を乗っ取れるという査読前の研究「KidnapRAG」が2026年7月に公開されました。自社でAIチャットや社内ナレッジ検索を導入・検討している情シスは、他人事ではありません。本記事では、この攻撃の仕組みと、実務で今押さえるべき論点を整理します。
この記事でわかること
- RAGポイズニング(RAG汚染)とは何か、なぜ怖いのか
- 新研究「KidnapRAG」が示した“ブラックボックス”攻撃の新しさ
- 社内AI導入を進める情シスが今すぐ確認すべき公的指針
※本記事が扱う論文は、査読前のプレプリント(arXiv投稿)です。結果は今後の検証で変わりうるため、断定的に受け取らず「こういう攻撃が研究レベルで実証されつつある」という視点でお読みください。
RAGポイズニングとは?
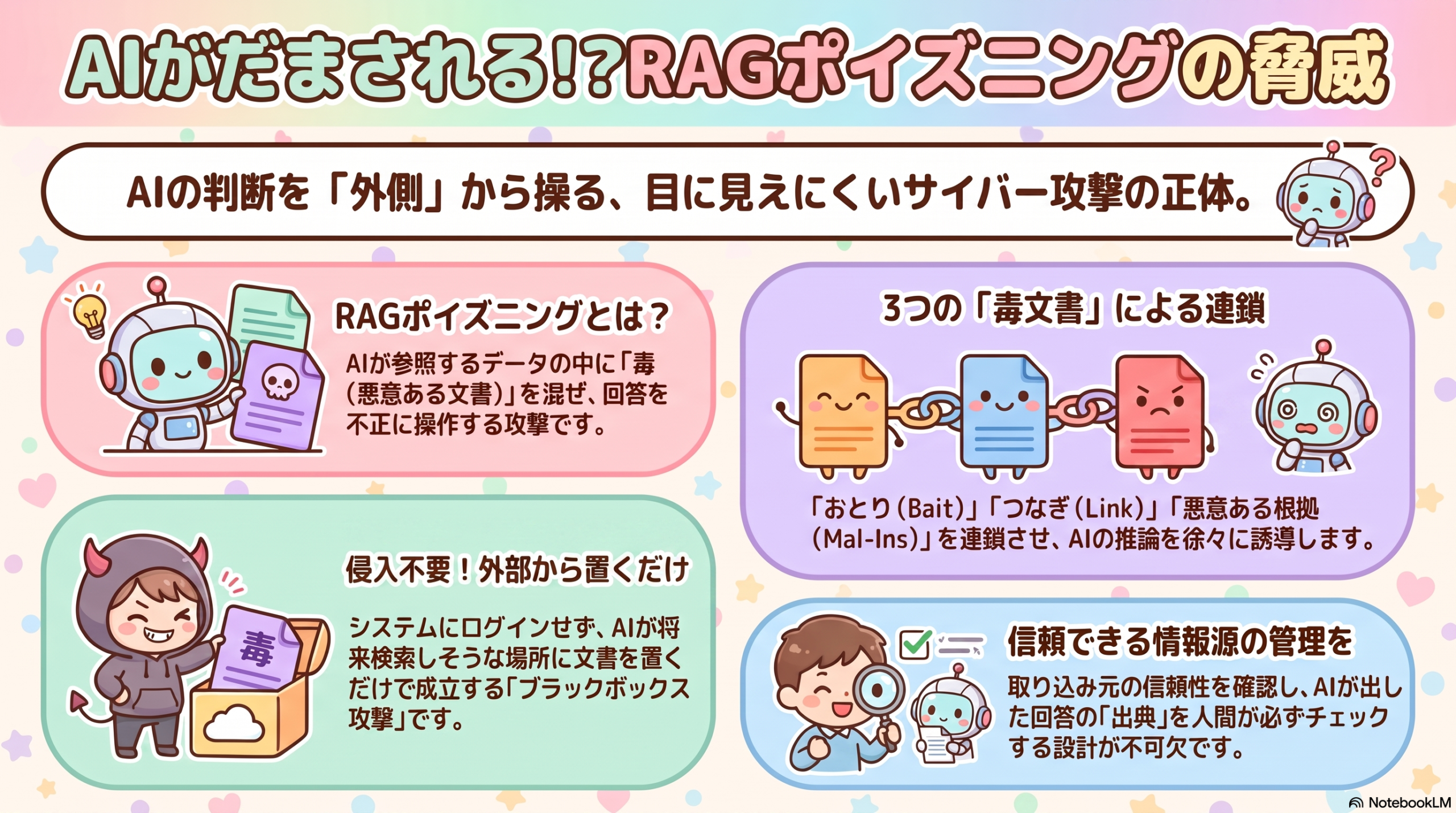
RAGポイズニングとは、AIが回答を組み立てる際に参照する外部文書(検索対象データ)に、攻撃者が悪意ある文書を紛れ込ませ、AIの出力や判断を意図した方向へ誘導する攻撃です。
RAG(Retrieval-Augmented Generation)は、質問に関連する文書をデータベースから検索し、その内容を根拠にLLMが回答を生成する仕組みです。社内規程の問い合わせ対応、製品マニュアル検索、問い合わせ自動応答など、企業導入が急速に進んでいます。検索対象に外部の公開情報(Webページ、共有ドキュメント、公開ナレッジ)が含まれる場合、そこに毒を仕込めるのがRAGポイズニングの入口です。
新研究「KidnapRAG」は何が新しいのか?
従来のRAG汚染は、単発の「毒入り文書」を検索結果に紛れ込ませるものが中心でした。近年広がるエージェント型RAG(Agentic RAG)は、検索と推論を何度も繰り返し、関連性の低い毒文書を自分で切り捨てるため、こうした単純な汚染に比較的強いとされてきました。
KidnapRAGは、この「多段の推論」そのものを逆手に取ります。論文によれば、役割の異なる3種類の文書を連鎖させて仕込む点が新しさです。
- Bait(おとり):最初の検索で引っかかりやすくし、まず土俵に上げる文書
- Chain-Link(つなぎ):エージェントの「問いの言い換え(クエリ再構成)」を誘導し、攻撃者に都合のよい検索へ向かわせる文書
- Mal-Ins(悪意ある根拠):最終的に攻撃者が用意した“証拠”を回答の根拠として掴ませる文書
研究チームは、この手法がブラックボックス条件——攻撃者はシステムプロンプトや内部の推論過程、検索エンジン、モデルのパラメータに一切アクセスできず、「外部から検索されうる文書を公開する」ことしかできない状況——で成立することを示しました。論文では、複数のフレームワークとLLMにわたり、既存の汚染手法を一貫して上回ったと報告されています。攻撃が進むにつれ本来の検索意図が徐々に弱められ、検索が攻撃者側へ誘導され、攻撃者が用意した根拠への依存度が高まっていく、という分析です。
なぜ情シスに関係するのか?
ポイントは「内部に侵入しなくても成立する」ことです。攻撃者に必要なのは、あなたの会社のAIが将来参照しうる場所に文書を置くことだけ。たとえば公開Webページ、外部の共有フォルダ、取り込み対象のオープンな情報源などです。ファイアウォールの内側に入る必要がないため、従来の「外部からの侵入を防ぐ」発想だけでは捕捉しづらいのが厄介な点です。
汚染が成功すると、AIが自信たっぷりに誤った回答を返す、特定の製品・判断へ誘導する、あるいは不適切な操作を実行する、といった被害が考えられます。社内問い合わせボットが誤った規程を案内すれば、業務そのものが静かに歪みます。
現場目線の課題:どこまで“取り込み元”を把握できているか
率直に言えば、多くの現場でAI導入は「まず動かす」が先行し、検索対象データの棚卸しは後回しになりがちです。どの情報源を、どんな信頼度で、誰の承認で取り込んでいるのか——ここを即答できる組織はまだ多くありません。エージェント型RAGは「自律的に賢く動く」ことが売りですが、その自律性ゆえにどの根拠を採用したのか人間が追いにくいという運用上の泣きどころがあります。限られた人員で、日々増える取り込み元まで完全に目を配るのは正直しんどい、というのが実感ではないでしょうか。だからこそ、後述の“基本に忠実な設計”が効いてきます。
情シスはどうすべきか?(公的指針・フレームワークへ)
個別の対策を自前で並べるより、まず体系化された指針を土台にするのが近道です。RAG/LLMアプリの実務では、OWASP Top 10 for LLM Applications(2025年版)が定番で、今回の話題に直結する項目があります。
- LLM04: Data and Model Poisoning——学習・ファインチューニング・埋め込みデータへの汚染を扱う項目。RAGの取り込みデータの信頼性管理に直結します。
- LLM08: Vector and Embedding Weaknesses——ベクトルDB・埋め込み特有の弱点(汚染文書の混入、テナント越しの情報漏れ、権限バイパス等)を扱う項目。RAGパイプライン設計時の必読ポイントです。
これらを踏まえた基本の勘所は、「取り込み元の信頼区分」「出典の検証と表示」「権限・テナント分離」「人間の最終確認」を設計段階で組み込むこと。特に、回答の根拠となった文書の出典をユーザーに提示し、不自然な誘導に気づける導線を残すことが重要です。あわせて、利用者側にも「AIの回答は根拠を確認する」という啓発を地道に行う必要があります。国内の実務者向けには、IPAの中小企業の情報セキュリティ対策ガイドラインや対策のしおりが、組織全体の基本動作を固めるうえで役立ちます。関連する脅威は研究・論文カテゴリでも継続的に取り上げています。
限界・留意点:どこまで真に受けるべきか
繰り返しになりますが、これは査読前の研究であり、特定の実験設定・データセット・モデルでの結果です。すべてのRAG構成で同じ再現性があるわけではなく、防御側の対策も進みます。論文の抄録では具体的な防御策の提示は限定的で、「こういう攻撃が理論上・実験上成立しうる」という警鐘として受け止めるのが適切です。過度に恐れて導入を止める必要はありませんが、「取り込みデータは信頼できる」という暗黙の前提を捨てる——この一点を設計に織り込むだけでも、堅牢性は大きく変わります。
まとめ
- RAGポイズニングは、AIが参照する外部文書に毒を仕込み、出力や判断を誘導する攻撃。社内AI・エージェント導入が進むほど現実的なリスクになります。
- 査読前研究「KidnapRAG」は、システムに侵入せず外部文書だけで、汚染に強いはずのエージェント型RAGの推論を乗っ取れることを示しました。
- 情シスはOWASP Top 10 for LLM(LLM04/LLM08)やIPAの指針を土台に、取り込み元の信頼管理・出典検証・権限分離・人間の最終確認を設計段階から組み込むことが要点です。
出典
- KidnapRAG: A Black-Box Attack for Hijacking Reasoning in Agentic Retrieval-Augmented Generation Systems(arXiv:2607.00422, 2026年7月1日投稿・査読前):https://arxiv.org/abs/2607.00422
- OWASP Top 10 for LLM Applications (2025):https://genai.owasp.org/llm-top-10/
- IPA 中小企業の情報セキュリティ対策ガイドライン:https://www.ipa.go.jp/security/guide/sme/index.html