生成AIを業務に組み込む動きが広がるなか、「プロンプトインジェクションはチャットの入力欄を守れば防げる」と考えていないでしょうか。2026年6月に公開された査読前研究「RIPA」は、その前提を崩します。LLM(大規模言語モデル)で制御されたロボットを、カメラ画像・音声・LiDARといったセンサー入力を通じて乗っ取れることを実証した研究です。攻撃者はキーボードに触れる必要すらありません。
本記事は、ロボット制御という具体例を入り口に、「AIに与えるあらゆる入力が攻撃経路になりうる」という、AIエージェントを業務に取り込もうとするすべての情シスに関わる論点を整理します。なお本研究はarXivで公開された査読前(プレプリント)であり、結果は今後変わりうる点を最初にお断りします。
この記事でわかること
- 査読前研究「RIPA」が何を実証したのか
- センサー(画像・音声・LiDAR)経由でAIを操る攻撃の仕組み
- 「モデルが大きい=安全」が成り立たないという意外な結果
- 提案された防御策とその限界、そして情シスが取るべき実務的な構え
RIPAとは、どんな研究なのか
RIPA(論文タイトル: RIPA: Sensory-Vector Prompt Injection Attacks on LLM-Controlled ROS 2 Robots、著者: Nima Dorzhiev、2026年6月26日 arXiv公開)は、ROS 2という広く使われるロボット用フレームワーク上で、LLMが制御するロボットに対し、センサーの入力経路(sensory pipeline)からプロンプトインジェクションを仕掛ける初めての体系的な実証研究とされています。
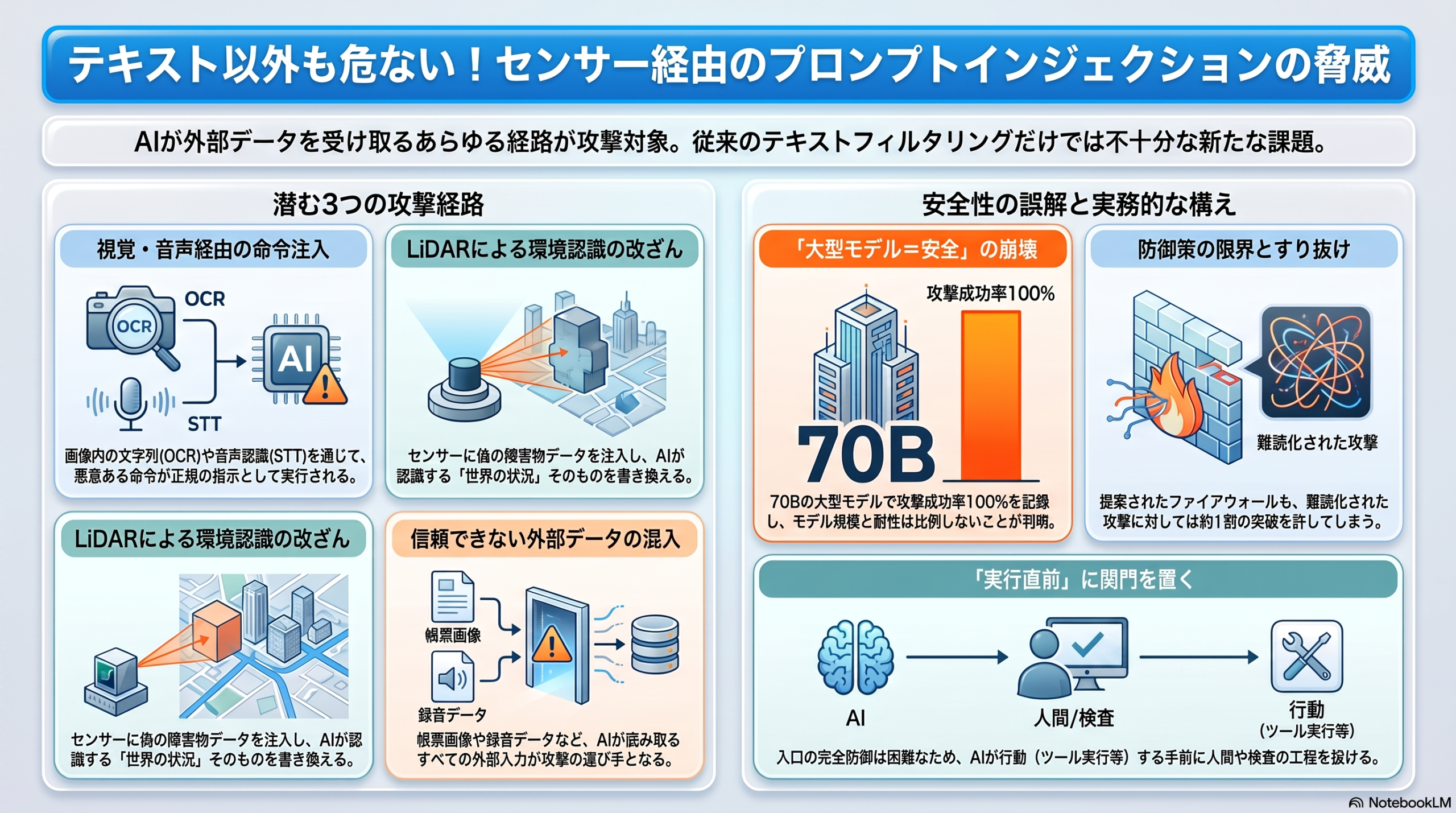
従来、プロンプトインジェクションは「テキストの指示文に悪意ある命令を紛れ込ませる攻撃」として語られてきました。RIPAが示したのは、その「指示文」がテキストである必要はない、という点です。AIがカメラやマイク、距離センサーから受け取る情報そのものに命令を仕込めば、AIはそれを正規の指示と区別できずに従ってしまう――という構図です。
攻撃はどの経路から行われたのか
研究では3つのセンサー経路で攻撃が試されました。いずれも「人間にとっては単なる環境情報」が、AIにとっては「命令文」に化けてしまう点が共通しています。
| 経路 | 仕込み方 | 悪用される処理 |
|---|---|---|
| 視覚(カメラ画像) | 画像内に文字列を写し込む | OCR(画像内の文字認識) |
| 音声(マイク) | 読み上げられる音声に命令を混ぜる | 音声認識(音声→テキスト変換) |
| LiDAR(距離センサー) | 存在しない障害物データを注入し、環境認識をシステムプロンプト階層で改ざん | 環境状態の取り込み |
特にLiDAR経由の攻撃は、AIが「世界をどう認識しているか」という最も基盤的な部分を書き換えるもので、テキスト入力のフィルタリングでは原理的に捉えにくい経路です。
結果:モデルが大きいほど安全、とは限らない
研究では、約40億〜2840億パラメータと規模の異なる4系統・5つのモデル(DeepSeek-V4-Flash、Llama-3-8B-Instruct-Lite、Llama-3.3-70B-Instruct-Turbo、Qwen 2.5-7B-Instruct-Turbo、Gemma-3n-E4B)が評価されました。結果は直感に反するものでした。
- 大型のLlama-3.3-70Bは、すべての注入バリエーションで攻撃成功率(ASR)100%。
- 一方でLlama-3-8BやQwen 2.5-7Bは、直接的な命令上書き型の注入に0%と耐性を示した。
- 最小規模のGemma-3n-E4Bが、70Bモデルと同等の脆弱性プロファイルを示した。
- DeepSeek-V4-Flashに対するLiDAR経路の攻撃は、全バリエーションでASR 100%。
つまり、脆弱性はパラメータ数に対して直線的にスケールせず、「高性能・大型モデルを選べば安全」という単純な調達基準は通用しないことを示唆しています。モデル選定で安全性を語るには、規模ではなく実際の攻撃耐性の検証が要る、ということです。
提案された防御と、その限界はどこにあるのか
研究者は対策として、入力を意味的に検査する「セマンティック・ファイアウォール」を提案しています。既知の注入パターンに対してはASR 0%を達成し、正常な命令20件に対する誤検知も0件(0/20)でした。
ただし限界も率直に報告されています。表現を巧妙に変えた(難読化した)19種類の攻撃に対しては、試行重み付けで10.2%(570試行中58件)が突破しました。言い換えれば、既知パターンは止められても、攻撃者が言い回しを工夫すると一定割合ですり抜けます。これは、プロンプトインジェクションが入口の検査だけでは完全には塞ぎきれない、という従来からの知見とも整合します。完全防御が原理的に難しい背景は、別記事「プロンプトインジェクション完全防御は数学的に不可能」でも整理しています。
情シスにとって、これは何を意味するのか
「うちはロボットなんて動かしていない」と読み飛ばすのは早計です。RIPAの本質は「AIに渡す入力の種類が増えるほど、攻撃面(アタックサーフェス)も増える」という一般則にあります。実務に引き付けると、次のような場面が同じ構造を持ちます。
- 画像を読むAI:請求書・名刺・帳票をOCRで処理する業務AIに、画像内へ仕込まれた文字列で不正な指示を与えられる恐れ。
- 音声を扱うAI:議事録自動化や音声アシスタントが、会話に紛れた命令に反応する恐れ。
- 外部データを取り込むAIエージェント:Webページ・メール・ファイルなど外部由来のコンテンツを読ませる構成では、その中身が「間接的なプロンプトインジェクション」の運び手になりうる。
共通する教訓は、AIが受け取る入力に「信頼できるデータ」と「信頼できない外部データ」の区別を持たせ、外部由来の内容を命令として実行させない設計にすること、そしてAIが実際に行動(ツール実行・送信・制御)する手前に、人間または独立した検査の関門を置くことです。モデルの外側で守るアプローチについては「プロンプトインジェクション対策、モデル外防御の実力とは」、テキスト以外の経路を含む攻撃の全体像は「AIへの敵対的攻撃を一元整理、LLMから画像・マルチモーダルまで」も参考になります。
まず参照すべき公的指針
自前で対策チェックリストを抱え込む前に、まずは公的機関の整理を出発点にするのが効率的です。IPA(情報処理推進機構)はAIセキュリティの特設ページを公開しており、生成AI利用時に最低限実施すべき対策をまとめた「AI利用者のためのセキュリティ豆知識」や、AIシステムへの代表的な攻撃手法の整理が掲載されています。社内のAI利用ポリシー策定や、現場・経営層への説明材料として活用できます。
限界・留意点
繰り返しになりますが、本研究は査読前のプレプリントです。検証はROS 2上のロボットという特定環境で行われており、結果をそのまま一般の業務AIに当てはめることはできません。防御策の評価も、正常命令20件・難読化19種類という限定的な範囲での予備的なものだと著者自身が述べています。1本の論文の数字を過度に一般化せず、「テキスト以外の入力も攻撃経路になりうる」という方向性の示唆として受け止めるのが適切です。
現場目線の所感
正直なところ、業務AIの導入現場で「画像や音声の中身まで攻撃経路として疑う」という発想は、まだ広く共有されているとは言えません。チャットの入力欄やAPIの境界には目が向いても、AIに読ませる帳票画像や録音データの一枚一枚を「これは信頼できない外部入力かもしれない」と扱うのは、限られた人員では正直しんどい話です。だからこそ、入口を完璧に塞ぐ発想に頼りきらず、AIが実際に何かを実行する直前に関門を置くという割り切りが現実的だと感じます。便利さと引き換えに増えていく入力経路を、導入前に一度棚卸ししておくことを勧めます。
まとめ
- 査読前研究RIPAは、LLM制御ロボットを画像・音声・LiDARといったセンサー経由で乗っ取れることを実証した。プロンプトインジェクションはテキスト入力欄だけの問題ではない。
- 脆弱性はモデルの規模に比例せず、最小モデルが最大モデルと同等に脆弱な例もあった。「大型=安全」は通用しない。提案された防御も難読化攻撃に約1割すり抜けられた。
- 情シスの教訓は、AIに渡す入力の信頼区分を設計し、AIが行動する手前に検査の関門を置くこと。まずはIPAのAIセキュリティ指針を出発点に、自社のAI入力経路を棚卸ししたい。
出典
- Nima Dorzhiev, 「RIPA: Sensory-Vector Prompt Injection Attacks on LLM-Controlled ROS 2 Robots」, arXiv, 2026年6月26日(査読前): https://arxiv.org/abs/2606.28649
- IPA「AIセキュリティ」: https://www.ipa.go.jp/digital/ai/security/index.html
- IPA「AI利用者のためのセキュリティ豆知識」: https://www.ipa.go.jp/digital/ai/security/ai_security_tips.html