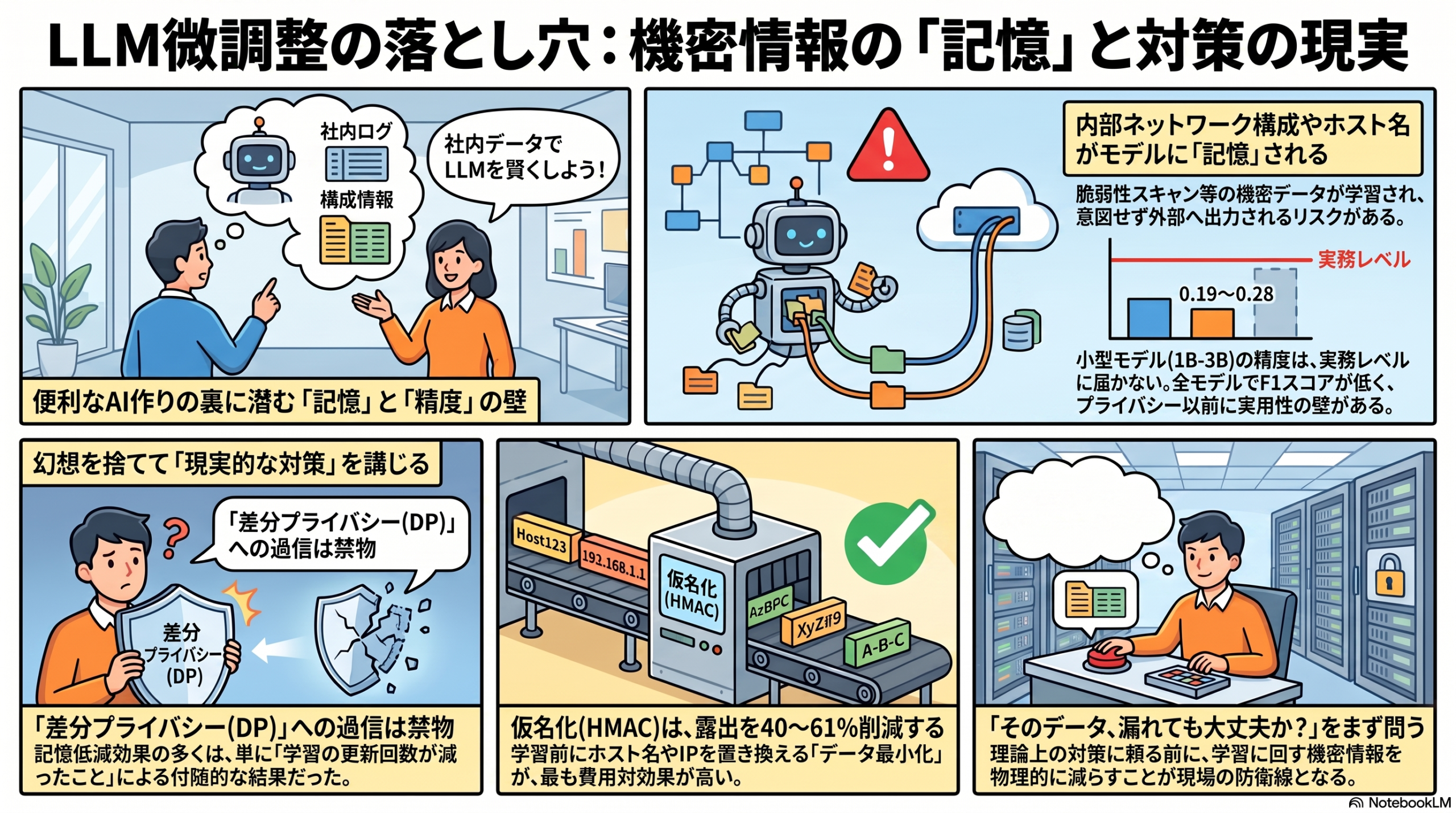
自社のセキュリティログや脆弱性スキャン結果を使ってLLM(大規模言語モデル)を微調整(ファインチューニング)すれば、社内事情に詳しい便利なAIが作れる——そう考える情シス・CSIRTは増えています。しかし、その学習データに含まれる内部ネットワーク構成やホスト名がモデルに「記憶」され、後から引き出されてしまうリスクがあります。本記事では、この記憶(memorization)の問題を実証的に分解した査読前の研究を取り上げ、差分プライバシーや仮名化がどこまで効くのか、情シスは何に注意すべきかを実務目線で読み解きます。
先に結論です。(1) 社内データでの微調整は内部情報の記憶・漏洩リスクを伴う。(2) 「差分プライバシーを使えば安心」とは限らず、効果の多くが別要因で説明できる場合がある。(3) 小型モデルを少ない予算で微調整しても、実務で使える精度に届かないことがある——という、過度な期待に冷や水を浴びせる結果でした。
この記事でわかること
- 社内のセキュリティデータでLLMを微調整するときの「記憶(漏洩)」リスクの正体
- 差分プライバシー(DP-SGD)や仮名化(HMAC)の効果と、見落としがちな落とし穴
- 小型モデル微調整の現実的な精度と、情シスが今取るべき構え
どんな研究か(1文で)
CSIRT(セキュリティインシデント対応チーム)が脆弱性スキャン記録で小型言語モデル(10億〜30億パラメータ)を微調整する場面を想定し、プライバシー保護手法が「モデルへの記憶」をどれだけ減らせるかを実証的に切り分けた研究です(Cristhian Kapelinski、Diego Kreutz、2026年6月26日 arXiv公開、査読前のプレプリント)。
そもそもなぜ問題かというと、脆弱性スキャンの記録には自社の内部ネットワークの構成・ホスト・脆弱性の所在といった機微情報が並びます。これをそのまま学習させると、GDPRやLGPD(ブラジルの一般データ保護法)などの規制下でプライバシーリスクになりうる、という問題意識です。
何が新しく、何が分かったのか
研究では、何も対策しない素の微調整を基準に、次の手法を比較しています。
- DP-SGD(差分プライバシーを組み込んだ学習。プライバシー予算ε=2 と ε=8 を検証)
- HMACによる仮名化(識別子をハッシュ化して置き換える前処理)
- QLoRA+大きなバッチでの学習
論文の主張で特に注目すべきは、「差分プライバシーで記憶が減った」と見える効果の大部分が、実は別の要因で説明できたという点です。
「DPが効いた」の正体は、更新回数の少なさだった?
研究は、最適化(オプティマイザ)の更新回数をそろえた対照条件を置いて検証しました。すると、観測された記憶の減少のうち66〜132%が「更新回数を減らしたこと」だけで再現できたといいます。言い換えると、DP-SGDがもたらす追加の(測定可能な)記憶低減はほぼ確認できなかったという結果です。
これは「差分プライバシーに意味がない」という話ではありません。DP-SGDは形式的なプライバシー保証(理論上の上限)を与えます。ただし、「記憶が減ったように見える」という観測上の効果を、そのままDPの威力と解釈してはいけない——というのが実務への警告です。
仮名化(HMAC)は素直に効いた
一方、識別子をHMACで仮名化する前処理は、露出を40〜61%削減し、二次的な記憶対象(仮名化していなければ記憶されていたであろう識別子)が生まれるのを防いだと報告されています。地味ですが、学習前にデータから機微な識別子を落とすという古典的なデータ最小化が、相応に効くことを示しています。
そもそも小型モデルは実用精度に届かなかった
もう一つ重い指摘があります。検証した全96個のアダプタにおいて、4-shotプロンプティングでのF1スコアは0.19〜0.28にとどまりました。つまり、今回試した学習予算の範囲では、1B〜3Bの小型モデルはCSIRT業務に使える精度に達しなかったということです。プライバシーを守る以前に、そもそも「役に立つか」の壁が立ちはだかった形です。
情シス・CSIRTの実務にどう効くか
この研究は限定的な設定の査読前報告ですが、社内でAI活用を検討する立場には示唆が多くあります。
| 論点 | 実務での受け止め方 |
|---|---|
| 学習データの中身 | 脆弱性スキャン結果・構成情報・ログは、そのまま学習させると内部情報が記憶・漏洩しうる「機微データ」。安易に投入しない。 |
| 差分プライバシー(DP) | 「DPを入れたから安全」と説明資料に書かない。理論保証と実測の記憶低減は別物。εの値と前提を理解した上で使う。 |
| 仮名化・最小化 | 学習前にホスト名・IP・識別子を仮名化/除去する前処理は費用対効果が高い。まずここから。 |
| 小型モデルへの期待 | 「小さく安く自社専用モデル」は現時点では精度の壁がある。PoCで実用精度を必ず検証してから本番判断を。 |
現場目線の所感
正直なところ、「社内データで自前LLMを育てたい」という相談は現場で増えています。ベンダーのデモは魅力的で、経営層も乗り気になりがちです。しかしこの研究が突きつけるのは、守りの面(情報漏洩)でも攻めの面(精度)でも、思ったほど簡単ではないという現実です。
特に怖いのは、「差分プライバシー対応」とうたわれた構成を額面どおり信じてしまうことです。担当者がεの意味や前提を理解しないまま「対策済み」と上に報告すれば、いざ漏洩が起きたときに説明責任を果たせません。機微な社内データを学習に回す前に、まず仮名化・最小化で機微情報そのものを減らす——この順序を崩さないことが、限られた人員で運用する現場の防衛線になります。
限界・留意点
- 査読前(プレプリント)の研究であり、結果は今後変わりうる。1本の論文を過度に一般化しない。
- 対象は1B〜3Bの小型モデルと限られた学習予算。より大きなモデルや潤沢な計算資源では結論が変わる可能性がある。
- 評価指標(F1、記憶の測り方)や攻撃想定が特定の設定に依存する。自社の用途・データに即した検証が別途必要。
情シスはどうすべきか(公的指針の活用)
自前で長大なチェックリストを作る前に、まずは公的な指針で全体像を押さえるのが近道です。組織でのAI活用・データの取り扱いの土台として、IPAの中小企業の情報セキュリティ対策ガイドラインや、機微情報を扱う前提としての対策のしおり(利用者啓発向け)が参考になります。AIに学習させてよいデータの線引きは、最終的に「そのデータが漏れたら困るか」という素朴な問いに立ち返ること、そして関係者へのユーザ教育・啓発を地道に続けることが効きます。
関連して、AIに社内権限を渡す際のリスクはLLMエージェントが「知りすぎる」問題でも整理しています。攻撃側の視点はAIへの敵対的攻撃の一元整理やプロンプトインジェクション対策もあわせてご覧ください。
まとめ
- 社内のセキュリティデータでLLMを微調整すると、内部構成が「記憶」され漏洩しうる。学習前のデータ最小化・仮名化が第一歩。
- 「差分プライバシー=安全」と短絡しない。観測上の記憶低減は更新回数など別要因で説明できる場合があり、理論保証と実測は切り分けて理解する。
- 小型モデルの自前微調整は現時点で精度の壁がある。本番投入の前に、自社データでの実用精度を必ず検証する。
出典
- Cristhian Kapelinski, Diego Kreutz, “Decomposing Memorization Reduction in Privacy-Preserving Fine-Tuning of SLMs for CSIRTs,” arXiv:2606.28479(2026年6月26日公開、査読前): https://arxiv.org/abs/2606.28479
- IPA「中小企業の情報セキュリティ対策ガイドライン」: https://www.ipa.go.jp/security/guide/sme/index.html
- IPA「対策のしおり」: https://www.ipa.go.jp/security/guide/shiori.html