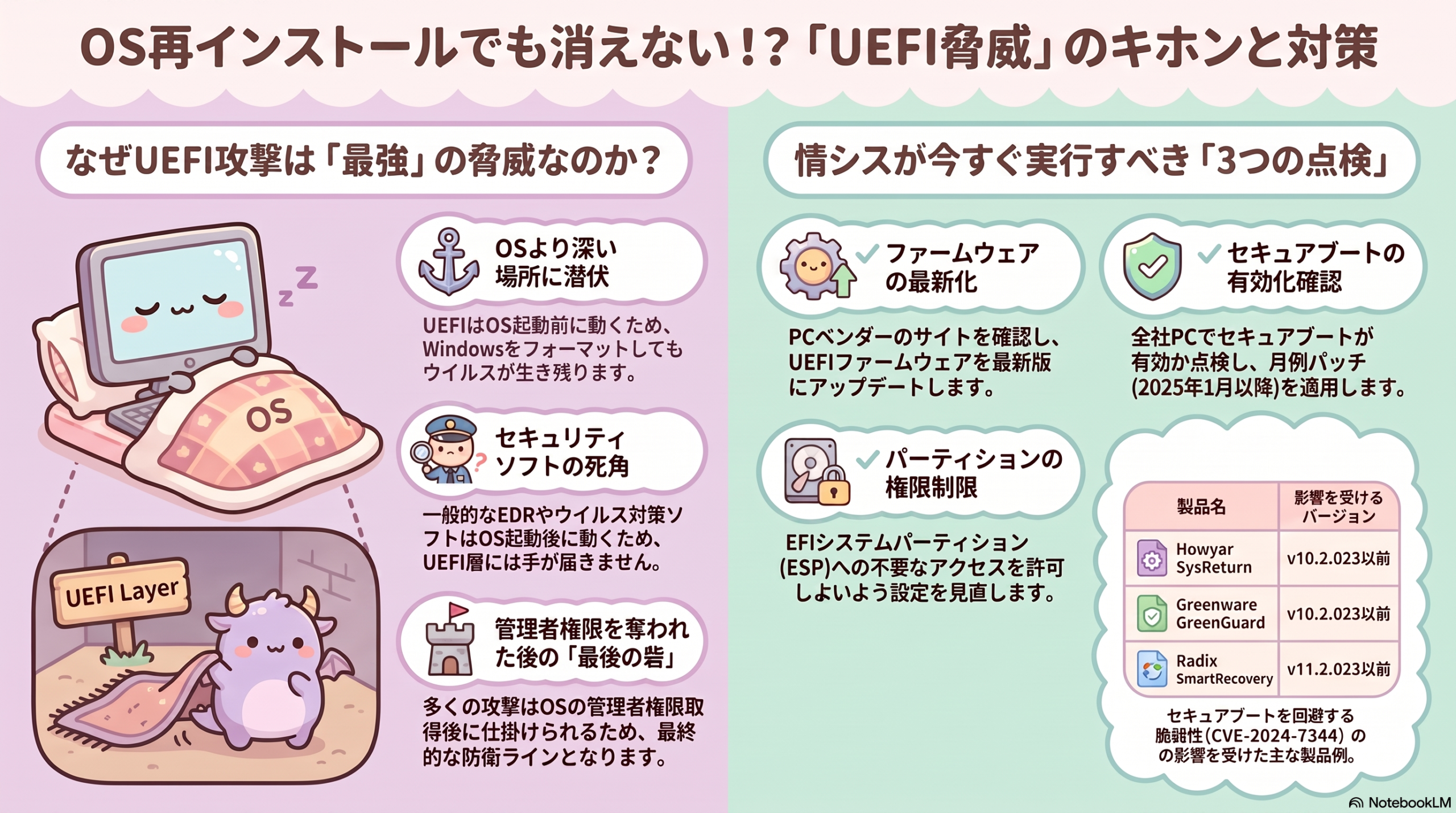
LLMエージェントの普及とともに、その基盤プロトコルを狙う攻撃が高度化している。2026年6月、arXivに公開された研究「ShareLock」は、Model Context Protocol(MCP)サーバーに仕込んだ悪意ある命令を複数のツール説明に分散・秘匿する手法を提案し、主要LLMに対して平均90%超の攻撃成功率を示した。自社でMCPを活用しているか検討中の情シス担当者は、このリスクを把握しておく必要がある。
この記事でわかること
- MCPとツール中毒攻撃(TPA)の基本構造
- ShareLockが何を新しくしたか(分散型・検知回避の仕組み)
- 情シスが今すぐ確認すべき実務上のポイント
- 研究の限界(査読前プレプリントであること)
MCPとは何か――LLMエージェントの「道具箱」
MCP(Model Context Protocol)は、LLMと外部ツール・データソースをつなぐオープンプロトコルで、Anthropicが策定しモダンなエージェントエコシステムの事実上の標準となりつつある。メールの送受信、データベース検索、コード実行など、LLMが外部システムを呼び出す際の「共通規格」と考えるとわかりやすい。
MCP環境ではMCPサーバーがツールを提供し、LLMはそのツール説明(tool description)を読んで適切なツールを選択・実行する。この「ツール説明を信頼する」設計が今回の攻撃の突破口になる。
既存の脅威:単一ツール中毒攻撃(TPA)
従来から知られる「ツール中毒攻撃(Tool Poisoning Attack、TPA)」では、悪意ある攻撃者が管理するMCPサーバーのツール説明に隠し命令を仕込む。LLMがその説明を読み込んだ瞬間、機密データの外部送信や意図しない操作を実行させることができる。
ただし単一ツールのTPAは、ツール説明を静的解析・キーワードスキャンで監査することで一定程度検知できる。
ShareLockが変えたもの――秘密を「分割して隠す」
ShareLockが提案するのは、シャミアの秘密分散(Shamir’s Secret Sharing)を悪用した多段構造の攻撃だ。
攻撃の流れ
- 命令の分割:悪意ある命令を「シェア」と呼ぶ複数の断片に分割する。各シェアは単独では意味をなさない無害な文字列に見える。
- 複数ツールへの埋め込み:分割したシェアを複数のMCPツール説明に散りばめる。個々のツール説明をスキャンしても怪しい文字列は見当たらない。
- 再構成トリガー:サーバー更新のタイミングや特定条件で、LLMが複数ツールを呼び出した際にシェアが集約され、元の命令が復元・実行される。
論文では4種類の複数ツールシナリオを評価し、主流LLMで平均90%以上の攻撃成功率を達成した。また、情報理論的な秘匿性から「適度な監査」に対する耐性が高いことも示されている。
情シスにとって何が問題か
企業のシステム部門でAIエージェントやMCP対応ツールの導入・評価を進めている場合、以下のリスクを認識する必要がある。
| リスク項目 | 内容 |
|---|---|
| サードパーティMCPサーバー | 外部ベンダーや公開レジストリ経由のMCPサーバーには、毒入りツール説明が含まれる可能性がある |
| 静的スキャンの限界 | 分散された各シェアは無害に見えるため、ルールベースの検知ツールでは見落とす可能性が高い |
| 更新タイミングの悪用 | サーバー更新時にトリガーが仕掛けられるため、定点観測だけでは変化に気づきにくい |
| エージェントの権限範囲 | メール送信・ファイルアクセス等の権限をエージェントに与えている場合、被害が拡大しやすい |
現場目線:MCPはまだ「信頼前提」が強すぎる
率直に言えば、MCPを含む現世代のLLMエージェントはツール説明を無批判に信頼する設計が標準だ。エージェントが呼び出すツールがどの組織が管理し、説明文に何が書かれているかを運用担当者が全件確認するのは現実的でない。人員が限られる情シス部門では特にそうだ。
社内に「AIエージェント活用の相談が来ているがどこまで許可すべきか」という状況があるなら、まず使用するMCPサーバーの出所と管理者を明確にすることを前提条件にすることを強く勧める。便利さと引き換えに外部への経路を無制限に広げることは、このShareLock型の攻撃が現実化したときに取り返しのつかない被害につながりうる。
情シスはどう動くか
現時点では、AIエージェントやMCPの公式セキュリティガイドラインとして参照できる日本語の公的指針は限定的だ。IPAの「AIセキュリティ」関連ページや、JPCERT/CCの動向を継続的に確認しつつ、以下の運用観点を社内で整理しておきたい。
- MCPサーバーの許可リスト管理:社内エージェントが利用できるMCPサーバーを明示的に承認制にする
- 最小権限の原則:エージェントに与える権限はメール送信・外部通信など高リスク操作を最小限に
- ツール説明の変更検知:利用中のMCPサーバーのツール説明に変更があった場合にアラートを上げる仕組みを検討する
- ログ・監査:エージェントがどのツールを呼び出したかのログを保全し、異常な呼び出しパターンを監視する
IPAが公開するAI関連セキュリティ情報(IPA セキュリティ)も定期確認しておくことを推奨する。
研究の限界と留意点
本研究はarXiv公開のプレプリント(arXiv:2606.27027v1、2026年6月26日公開)であり、査読前の研究であることに注意が必要だ。実験条件や評価手法によっては結果が変わりうる。また攻撃コードの公開状況・悪用の現実性については論文から読み取れる情報が限定的であり、即座に同様の攻撃が野生で多発しているわけではない。ただし攻撃の原理自体は理論的に成立しており、MCP採用の加速を踏まえれば中期的なリスクとして念頭に置く価値がある。
まとめ
- ShareLockはMCPのツール説明に悪意ある命令を秘密分散で隠す攻撃手法で、主要LLMで90%超の成功率を実験的に示した(査読前研究)。
- 単一ツールの静的スキャンでは検知が難しく、サードパーティMCPサーバーの利用は特に注意が必要。
- 情シスは使用MCPサーバーの許可リスト管理・最小権限・ログ監視を基本方針として、AIエージェント導入の安全基準を今から整えておくことが求められる。
出典
- Agarwal, et al.「ShareLock: A Stealthy Multi-Tool Threshold Poisoning Attack Against MCP」arXiv:2606.27027v1(2026年6月26日)https://arxiv.org/abs/2606.27027
- IPA セキュリティ情報トップ: https://www.ipa.go.jp/security/