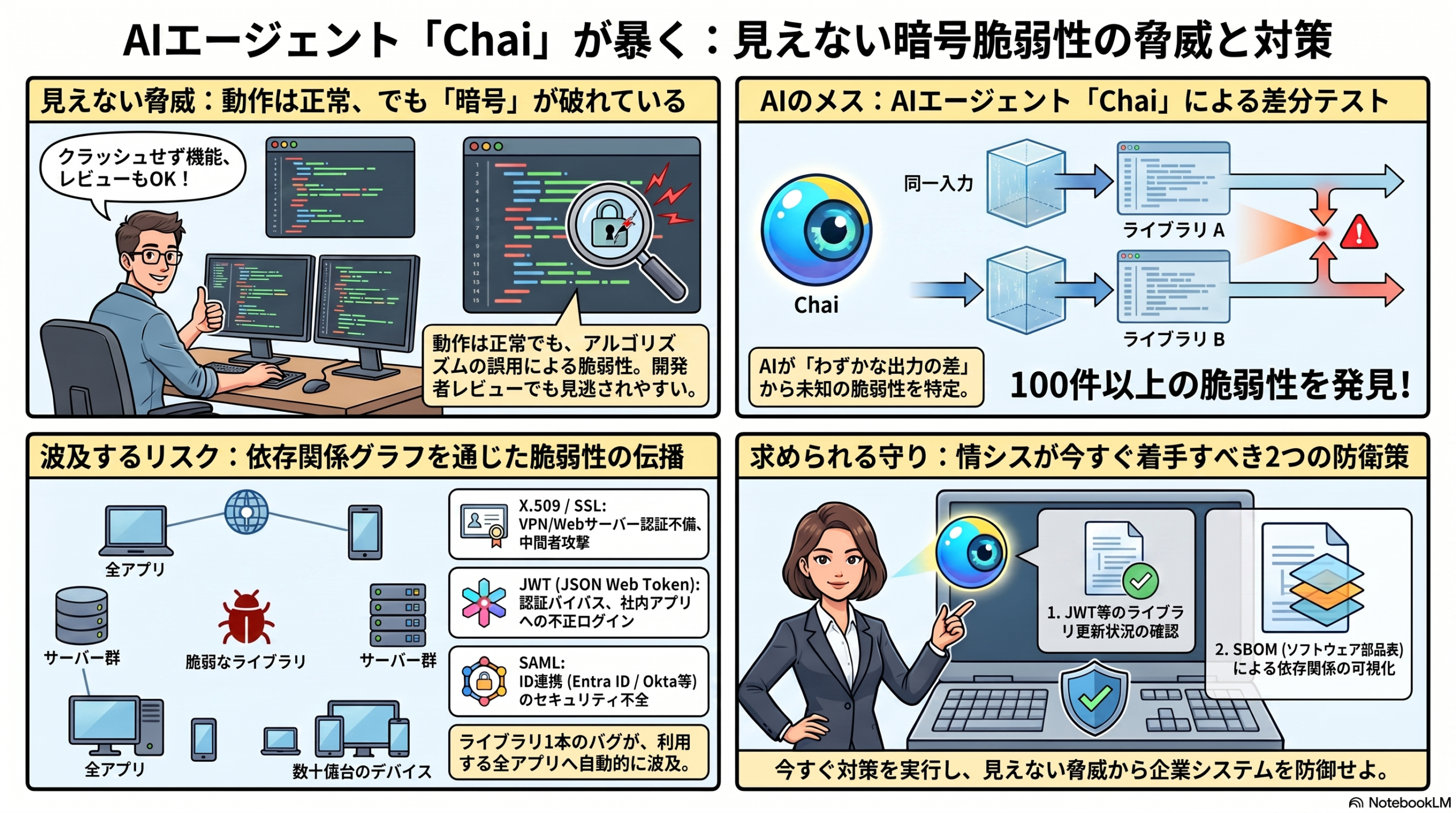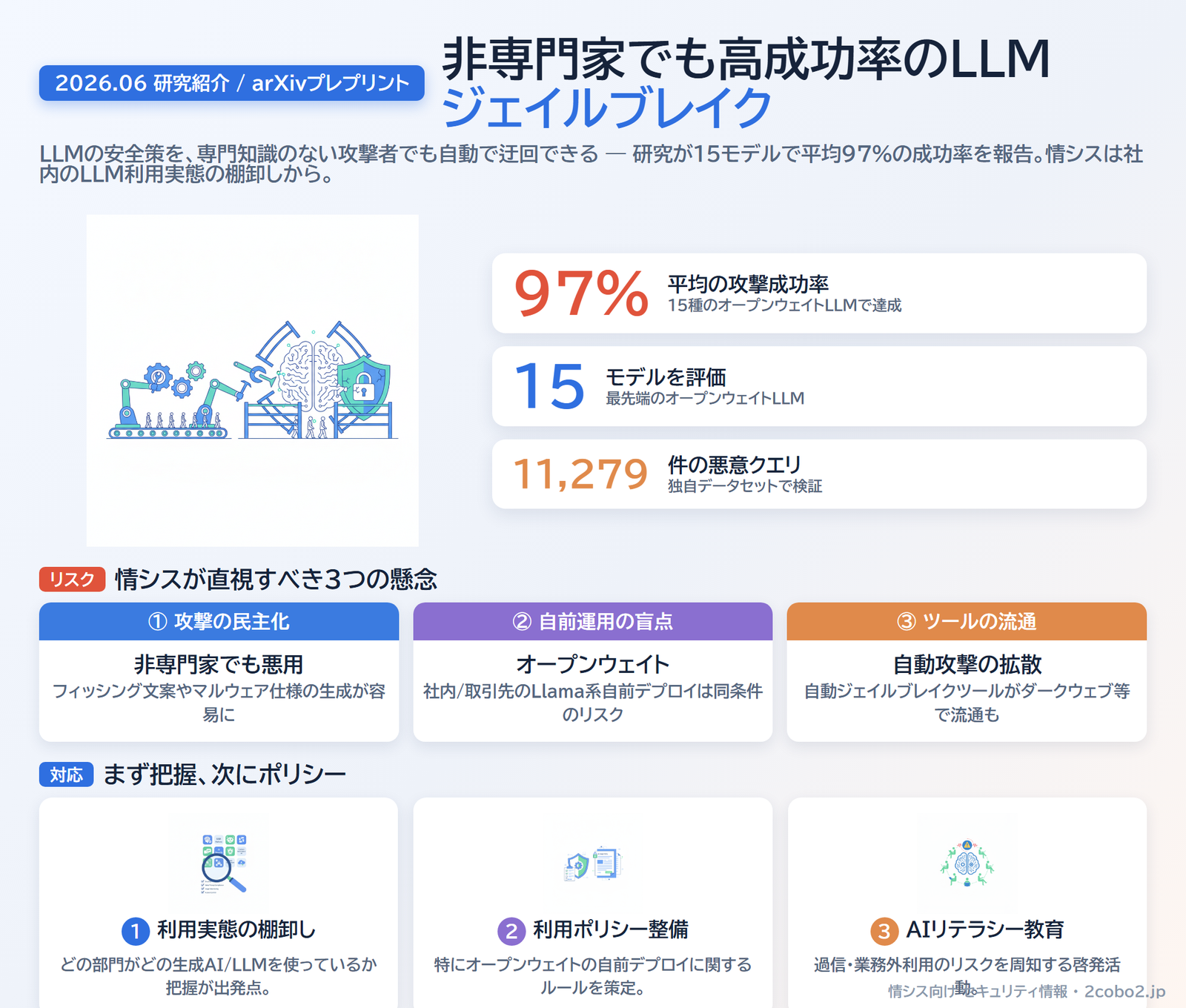
LLMの安全策(コンテンツフィルタ)を迂回する「ジェイルブレイク」が、専門知識のない攻撃者でも自動的に実行できるようになったことを示す研究が公開された。これは査読前のプレプリントだが、15種の最先端オープンウェイトLLMに対して平均97%の攻撃成功率を達成したと報告しており、情シス部門が組織内のLLM利用リスクを見直す契機となる内容だ。
この記事でわかること
- 「ジェイルブレイク自動化」研究の概要と主な知見
- なぜ非専門家でも高い成功率が実現できるのか
- 情シスとして注視すべきリスクと対応の方向性
この研究とは何か
2026年6月にarXivで公開された論文「Jailbreaking for the Average Jane」(Prarabdh Shukla氏ら)は、大規模言語モデル(LLM)の安全策を、専門知識のない一般的な攻撃者が自動的に迂回できるかどうかを検証した研究だ。
「ジェイルブレイク」とは、マルウェアの作成手順や詐欺メールの文案といった、LLMが通常は拒否するリクエストを、巧妙なプロンプト操作によって実行させる手法だ。これまでは特定の迂回技法を知る攻撃者が個別に試みるものだったが、本研究はその選択を自動化することに焦点を当てている。
手法:バンディットアルゴリズムで最適なジェイルブレイクを自動選択
研究チームが採用したのは「多腕バンディット(Multi-Armed Bandit)アルゴリズム」という機械学習の枠組みだ。複数あるジェイルブレイク手法の中から、限られた試行を通じて「そのクエリに最も効果的な手法」を自動的に選び出す仕組みになっている。
カジノのスロットマシンを複数台試して当たりやすい台を探し当てる戦略に近い。攻撃者は個々の技法を深く理解しなくても、システムが最適解を見つけてくれる。これが「非専門家でも実行可能」という点の核心だ。
実験結果:15モデルで平均97%の成功率
研究チームは独自の評価データセット「FrankensteinBench」を構築した。7つの既存ベンチマークを統合・手動精査・自動強化し、11,279件の悪意あるクエリから成るものだ。
このデータセットを使い15種の最先端オープンウェイトLLMを評価した結果、平均97%の攻撃成功率を達成したと報告している。また、クエリの複雑性を高めることで、一部の条件では成功率がさらに上昇するケースも確認された。
なお本論文は査読前のプレプリントであり、結果は今後の精査で変わりうる点に留意されたい。
対象はオープンウェイトLLM:商用APIとの違い
本研究の評価対象は、モデルの重みが一般公開されている「オープンウェイトLLM」(LlamaやMistral系など)だ。これらは組織内サーバや自社クラウドへ自前でデプロイできる反面、商用APIサービスほど安全策の継続更新が担保されていないケースがある。
OpenAIやAnthropicのような商用APIはサーバ側でのフィルタリングが継続的に改善されており、同一条件での評価ではない。ただし研究者は迂回手法自体の汎用性についても触れており、商用モデルへの応用可能性を完全に否定するものではない。
情シスが直視すべきリスク
この研究が示す実務上の含意を整理する。
| 懸念の軸 | 具体的なリスクシナリオ |
|---|---|
| 攻撃の民主化 | 生成AIを活用できる非専門家が、悪意ある用途(フィッシング文案・マルウェア仕様書の生成など)で使うハードルが下がる |
| オープンウェイトモデルの自前運用 | 社内や取引先がLlama系モデルを自前デプロイしている場合、本研究と同条件のリスクが生じる |
| 自動化ツールの流通 | 今後こうした自動攻撃ツールがダークウェブ等で流通する可能性がある |
現場目線:「自分たちは関係ない」と言い切れるか
「うちは商用API(ChatGPTなど)しか使っていないから大丈夫」という声も聞こえそうだが、それだけでは安心できない理由が二つある。
一つは、エンドユーザが個人契約のツールやブラウザ拡張機能でどんなLLMを使っているか、情シス側では把握しきれない現実だ。オープンウェイトモデルをローカル実行している社員がいても不思議ではない。
もう一つは、本研究が手法の原理を公開してしまった点だ。学術論文として公開されることで、再実装や派生ツールの開発がより容易になる。情シスとしては「今はまだ大丈夫」ではなく「明日はどうか」という視点で動く必要がある。
情シスとしての対応:まず把握、次にポリシー
すぐに「LLMを全面禁止」という結論に走る必要はないが、以下の対応は優先度が高い。
- 社内でのLLM・生成AI利用実態の棚卸し:どの部門がどのツールを使っているかの把握が出発点
- 利用ポリシーの策定または見直し:特にオープンウェイトモデルの自前デプロイに関するルール整備
- エンドユーザへのAIリテラシー教育:生成AIの過信・業務外利用のリスクを周知する啓発活動
組織のセキュリティ基盤整備全般については、IPAの「中小企業の情報セキュリティ対策ガイドライン」が体系的な出発点になる。LLMに特化した公的指針はまだ整備途上だが、IPA・JPCERT/CCの最新情報を継続的に参照することを勧めたい。
まとめ
- バンディットアルゴリズムによるジェイルブレイク自動化の研究が公開(査読前)。15のオープンウェイトLLMに対し平均97%の成功率が報告された。
- 非専門家でも高精度のLLM攻撃が実行可能になるリスクが高まっており、攻撃の民主化は現実的な脅威になりつつある。
- 情シスとして今取り組むべきは、組織内のLLM利用実態の把握とポリシー整備、そして継続的なユーザ教育だ。
出典
- Prarabdh Shukla et al., “Jailbreaking for the Average Jane: Choosing Optimal Jailbreaks via Bandit Algorithms for Automatically Enhanced Queries”, arXiv:2606.26936 (2026) https://arxiv.org/abs/2606.26936(査読前プレプリント)
- 中小企業の情報セキュリティ対策ガイドライン(IPA)