1通ずつ見れば無害なのに、会話を何ターンも積み重ねると有害な出力を引き出せる——。この「多段(マルチターン)ジェイルブレイク」に、会話全体を監視する多層ゲート型の防御「認知的ファイアウォール(Cognitive Firewall)」を提案した査読前の研究論文が、2026年7月1日にarXivで公開されました。社内チャットボットや生成AIを業務に組み込み始めた情シスにとって、「1メッセージ単位のフィルタでは守り切れない」という論点は、AIリスク評価を見直す材料になります。
この記事でわかること
- 「多段ジェイルブレイク」がなぜ従来のガードレールをすり抜けるのか
- 認知的ファイアウォールが採る「ゼロトラスト・多層ゲート」の考え方
- 自社でLLMを使う情シスが押さえておくべき実務的な示唆
※本記事は査読前のプレプリント(arXiv:2607.01277v1、2026年7月1日投稿)に基づいています。結果は今後の査読・改訂で変わりうる点に留意してください。
どんな研究か(1文で)
ユーザーとLLMのやり取りに割り込み、応答が利用者に届く前に「意図・権限・一貫性・出力リスク」を多層的に検査する独立した監視層を設計し、複数のジェイルブレイク・ベンチマークで評価した研究です。論文タイトルは「Cognitive Firewall: A Proactive, Zero-Trust, Multi-Gate Framework for LLM Safety」、Michele Guidaらによる投稿です(arXiv:2607.01277)。
多段ジェイルブレイクとは何か
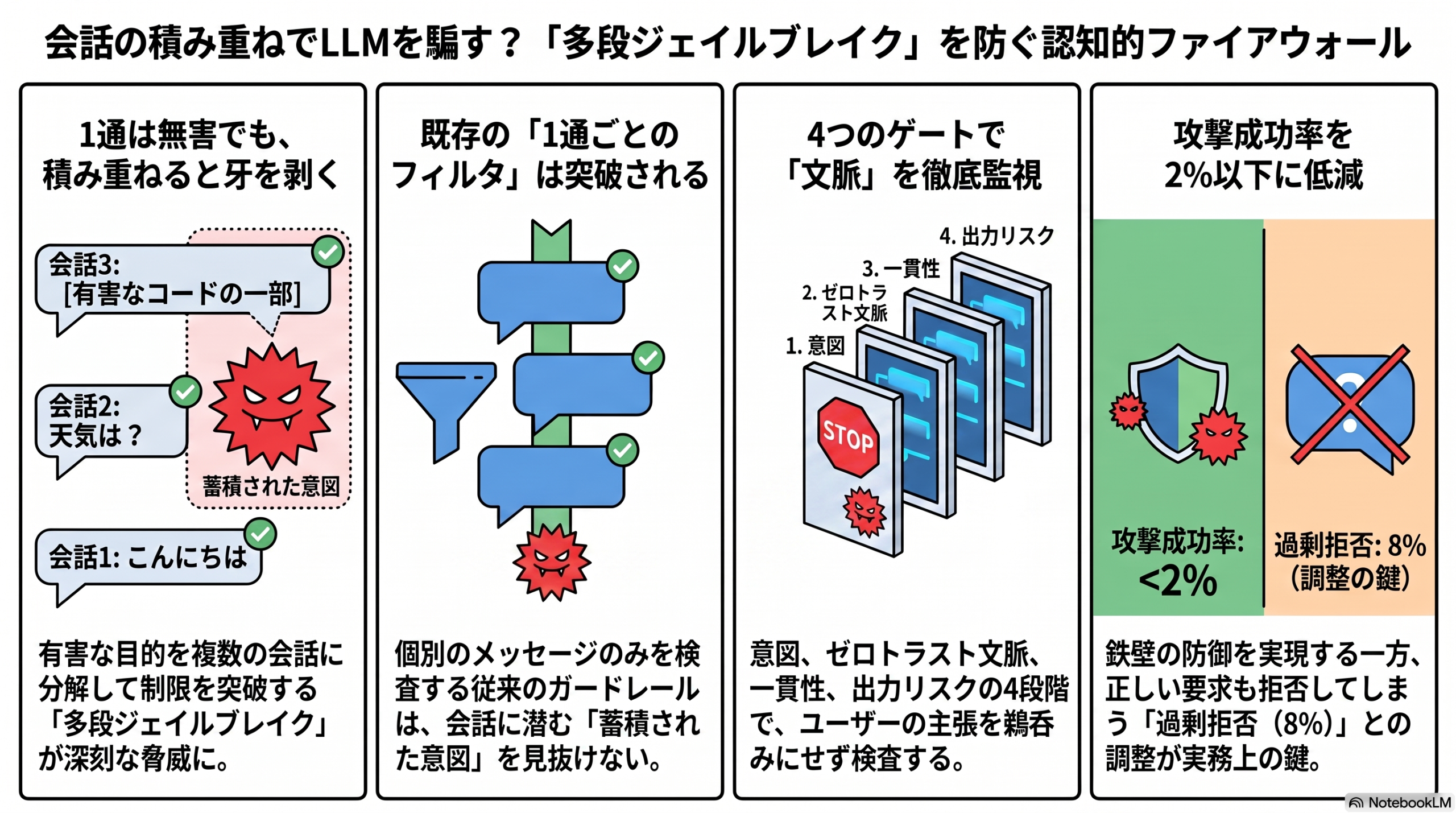
多段ジェイルブレイクとは、有害な要求を複数の会話ターンに分解し、どの1通も明確には危険に見えない形で少しずつ意図を積み上げてLLMの制限を突破する攻撃手法です。攻撃者は「役割を演じさせる」「架空の権限を主張する」「無害な質問を装って前提を積み上げる」といった手を組み合わせ、最終的に禁止されているはずの出力を引き出します。
本論文が指摘するのは、既存の実行時ガードレールの多くがプロンプトや応答を「個々のメッセージ」として単独評価している点です。この方式では、会話全体を通じて蓄積された意図(accumulated intent)を復元できず、主張された権限の真偽を検証できず、分割された有害戦略を検出しづらい、というわけです。1通ごとのフィルタが優秀でも、ターンをまたいだ攻撃には構造的に弱い、という問題提起です。
認知的ファイアウォールの仕組み――4つのゲート
提案手法は、LLMの前後に割り込む独立した監視層として、次の4つのゲートを順に通す「ゼロトラスト・多層ゲート」構成を採ります。ネットワークのファイアウォールになぞらえた設計思想です。
| ゲート | 役割 |
|---|---|
| 意図ゲート(Intent Gate) | 要求の裏にある「本当の目的」を推定する |
| ゼロトラスト文脈ゲート(Zero-Trust Context Gate) | ユーザーが主張する役割・権限を、鵜呑みにせず「未検証の証拠」として扱う |
| 一貫性ゲート(Consistency Gate) | 会話ターンをまたいだエスカレーションや、分割された攻撃戦略を検出する |
| 出力リスクゲート(Output Risk Gate) | 生成された応答候補を、利用者に届ける前に検査する |
ゲートの判定はエスカレーション方式で、どこか1つでも確度の高い危険信号が出れば対話をブロックし、なおかつ「なぜブロックしたか」を監査可能な形で残す設計とされています。ポイントは、主張された権限を検証せずに信じないという発想です。これは社内ネットワークで長く語られてきた「ゼロトラスト」の考え方を、LLMの会話文脈に持ち込んだものと言えます。
評価結果
論文は4つのジェイルブレイク・ベンチマークと、正常な(無害な)安全性テストセットで評価しています。報告されている主な数値は次の通りです。
- 3種類の攻撃セットで、攻撃成功率を2%以下に低減
- 最も難しい「人間が作り込んだ攻撃」では、攻撃成功率14%(=すべてを防げるわけではない)
- 過剰拒否(本来は答えてよい要求まで断ってしまう)率は8%
この「過剰拒否8%」という数字は、実務では見逃せない論点です。防御を強めれば正常な業務利用まで弾かれやすくなる、というトレードオフが数字で示されているからです。
情シスにとっての意味・現場目線の課題
正直なところ、社内でLLMを「文書作成の補助」程度に使っているだけなら、多段ジェイルブレイクはまだ遠い話に感じるかもしれません。ただ、自社で外部向けのAIチャットボットを公開したり、生成AIを業務プロセスに深く組み込んだりする段階になると、話は変わります。攻撃者は1通の露骨なプロンプトではなく、無害を装った会話の積み重ねで守りを崩しにくる——この視点を持っておくかどうかで、リスク評価の解像度が変わります。
もう一つ現場感覚として響くのは「過剰拒否」の存在です。安全側に振り切った設定は、正当な問い合わせをブロックして現場の不満やシャドーIT(勝手な外部AI利用)を招きます。限られた人員でチューニングを回す現場ほど、「守り」と「使い勝手」の綱引きは重い課題です。防御は導入して終わりではなく、拒否ログを見ながら調整し続ける運用が前提になる、という点は押さえておきたいところです。
なお本研究は、あくまで「独立した監視層をLLMの外側に置く」という設計提案です。会話全体の意図を追い、主張された権限を検証し、実行時に判定するという方向性は、AIエージェントの実行時ポリシー強制の議論とも通じます。単発の入力チェックだけでなく、やり取りの流れ(文脈)そのものを監視対象にするという潮流の一例として読むと理解しやすいでしょう。
情シスはどうすべきか
本研究は査読前の1本であり、そのまま製品として使えるわけではありません。過度な一般化は禁物です。そのうえで、LLMを業務利用する(あるいは検討する)情シスができる現実的な備えは次の通りです。
- 「1メッセージ単位の対策」で満足しない:導入するAIサービスやガードレールが、会話全体の文脈をどこまで見ているかをベンダーに確認する。
- 主張された権限を信じない設計を意識する:「私は管理者だ」といったユーザーの自己申告を前提に振る舞いを変えないよう、システム側の権限管理と切り離す。
- 過剰拒否と抜け穴の両方を監視する:ブロックログと成功した不審な対話の両面を定期的にレビューし、閾値を調整する。
- 高リスク用途は人間の確認を挟む:AIの出力を最終決定にしない領域を明確にする。
体系的な備えの出発点としては、自前で長大なチェックリストを作る前に公的指針を押さえるのが近道です。IPAは生成AIの導入・運用や、AI利用者向けの基礎資料を公開しています。まずはこちらで全体像を確認し、利用者への地道な啓発(「AIは巧妙な誘導で騙されうる」という前提の共有)につなげることをおすすめします。
- IPA「AIセキュリティ」ポータル:https://www.ipa.go.jp/digital/ai/security/index.html
- IPA「AI利用者のためのセキュリティ豆知識」:https://www.ipa.go.jp/digital/ai/security/ai_security_tips.html
関連して、単発の入力に潜むプロンプトインジェクションや、LLM・画像・マルチモーダルへの敵対的攻撃の全体像、さらにLLMエージェントが偽の障害を捏造する『死んだふり』の話題もあわせて押さえると、AIをめぐる攻撃面を体系的に理解できます。
限界・留意点
本研究は査読前のプレプリントであり、評価はベンチマーク上の結果です。実運用環境や、論文で使われていない新しい攻撃手法に対して同じ性能が出るとは限りません。攻撃成功率2%以下という数字も「人間が作り込んだ攻撃では14%」という条件付きであり、完全に防げる技術ではない点を冷静に受け止める必要があります。監視層を追加することによる応答遅延やコスト、過剰拒否による業務影響も、実装時には検討事項になります。「万能の解決策が登場した」ではなく、「会話全体を見る防御という方向性が具体化されつつある」と受け取るのが妥当です。
まとめ
- 1通ずつは無害に見える会話を積み上げてLLMの制限を突破する「多段ジェイルブレイク」に、会話全体を監視する多層ゲート型防御「認知的ファイアウォール」を提案した査読前研究がarXivに公開された。
- 意図・ゼロトラスト文脈・一貫性・出力リスクの4ゲートで会話文脈を検査し、主張された権限を検証せず信じない設計が特徴。3種の攻撃で成功率2%以下、一方で過剰拒否は8%というトレードオフも示された。
- 情シスは「1メッセージ単位の対策で満足しない」「主張された権限を信じない」「過剰拒否と抜け穴の両方を監視」を軸に、IPA等の公的指針を出発点に備えるとよい。
出典
- Michele Guida, Ruslan Shikhhamzayev, Sindhuja Penchala, Stefano Iannucci, Jiacheng Li, Shahram Rahimi, Noorbakhsh Amiri Golilarz「Cognitive Firewall: A Proactive, Zero-Trust, Multi-Gate Framework for LLM Safety」arXiv:2607.01277(2026年7月1日投稿、査読前プレプリント):https://arxiv.org/abs/2607.01277
- IPA「AIセキュリティ」:https://www.ipa.go.jp/digital/ai/security/index.html
- IPA「AI利用者のためのセキュリティ豆知識」:https://www.ipa.go.jp/digital/ai/security/ai_security_tips.html