社内文書を検索・要約させるRAG(検索拡張生成)の導入が急速に進んでいます。その心臓部にある「埋め込みモデル」が、返ってきた文書を観察するだけで外部から特定されうる――そんな攻撃手法を示した査読前の研究論文が公開されました。本記事では、論文「Embedding Inference Attack」(arXiv、2026年7月)の内容を情シス実務者の視点で噛み砕いて紹介します。
【重要】本記事で取り上げるのは査読前(プレプリント)の研究です。結果は今後の査読・追試で変わりうるため、断定は避け、あくまで「こういう攻撃の可能性が示された」という視点でお読みください。
この記事でわかること
- 「埋め込み推論攻撃(EIA)」がどんな攻撃かの1文要約
- なぜ社内RAGの担当者が知っておくべきなのか
- 実務で何を意識すればよいか(現実的な緩和策)
- この研究の限界と、過度に恐れないための注意点
埋め込み推論攻撃(EIA)とは何か
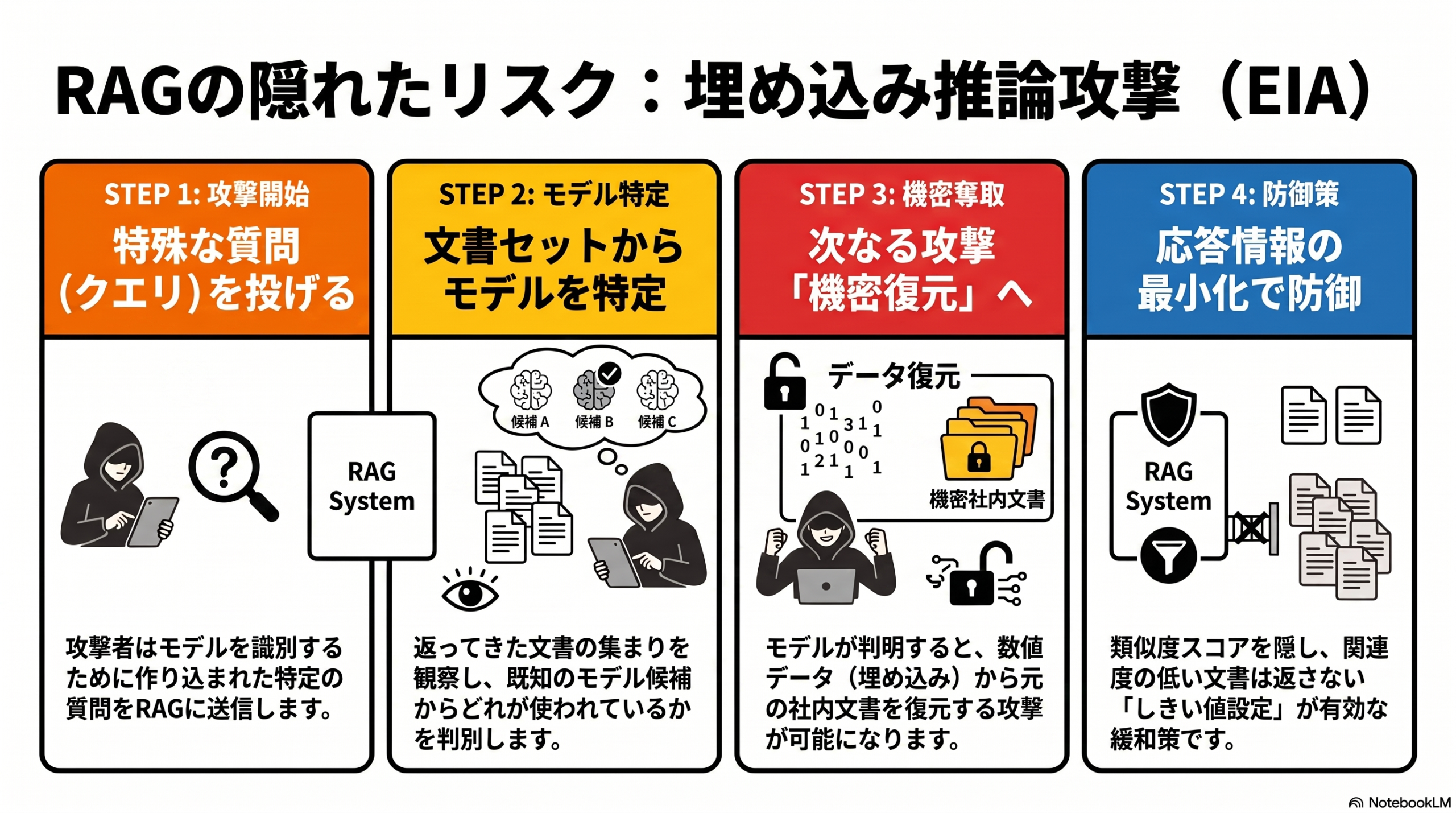
埋め込み推論攻撃(Embedding Inference Attack、EIA)とは、検索システムが返す文書の集合だけを手がかりに、その裏で使われている「埋め込みモデル」の種類を外部から言い当てる攻撃です。
少し用語を補足します。RAGやベクトル検索では、文書や質問を「埋め込み(ベクトル)」という数値の並びに変換する埋め込みモデルが使われます。どのモデルを使っているかは通常、APIの内側に隠されていて外からは見えません。この研究は、その「隠れているはずのモデル」を推定できてしまうことを示しました。
従来の攻撃と何が違うのか
これまでにも、埋め込みから元の文章を復元しようとする「埋め込み反転(inversion)攻撃」などが知られていました。ただし、こうした攻撃の多くは「攻撃者が使われているモデルを既に知っている」ことを前提としており、そこが実運用では高いハードルでした。
この研究が扱うのは、より現実に近いブラックボックス設定です。攻撃者が観察できるのは「返ってきた文書の(順位もスコアも付かない)集まり」だけ。それでも、狙って作った質問(tailored queries)を投げることで、候補となる複数の既知モデルの中から実際に使われているモデルを識別できた、と報告しています。
研究が示した主なポイント
論文の主張を、実務者が押さえるべき点に絞って整理します。
| 観点 | 研究が示したこと |
|---|---|
| 前提条件 | 類似度スコアも順位も見えず、返ってきた文書の集合だけを観察できる状況(=APIサービスで現実的) |
| 攻撃の成立 | 特定の質問を投げると、候補モデル群の中から使用中の埋め込みモデルを識別できた |
| リランカーがあっても | 再ランク付け(reranker)を防御として挟んでも、一部の質問は依然として識別に有効だった |
| 実RAGでの検証 | 実際のRAGシステムでも、作り込んだ質問がLLMの「意味不明な入力を拒否する」傾向をすり抜けたとされる |
| 緩和策 | 類似度のしきい値(threshold)設定などの対策を提案・評価 |
なぜ情シスが気にすべきか―「偵察」としての意味
「使っているモデル名がバレるだけ」なら大した問題ではないように見えます。しかし攻撃の世界では、相手の内部構成を知ること(フィンガープリンティング=偵察)は、次の攻撃の精度を上げる第一歩です。
たとえば前述の埋め込み反転攻撃は「モデルを知っていること」が前提でした。EIAでモデルを特定できれば、その前提が満たされ、次の段階として埋め込みから機微情報を復元する攻撃へつながりうる――という連鎖が想定されます。社内文書をインデックス化したRAGは、まさにその機微情報の塊です。
現場目線の所感
正直なところ、多くの現場では「どの埋め込みモデルを使っているか」はセキュリティ上の秘密として管理されていないのが実情ではないでしょうか。SaaSのRAG機能をそのまま使い、モデルの選定や更新はベンダー任せ、というケースも多いはずです。攻撃者にとってモデルが「隠れている」ことをうっすら防御と見なしていたなら、その前提は思ったほど堅くないかもしれない、という警鐘として受け止めるのが妥当だと感じます。とはいえ、これ単体で即座に情報漏えいが起きるわけではない点も冷静に押さえておきたいところです。
実務でどう向き合うか
この研究段階の内容に対して、いきなり大掛かりな対策を打つ必要はありません。まずは自社のRAG/ベクトル検索の「入口と出口」を見直す観点として活かすのが現実的です。
- 外部に開いたRAGの入出力を把握する:誰でも自由に質問を投げられる検索・チャットになっていないか。認証・レート制限・入力の妥当性チェックがかかっているか。
- 返す情報を絞る:類似度スコアや内部メタデータを、必要以上に応答へ含めていないか。論文が緩和策として挙げた類似度しきい値のように、「関連度が低い文書は返さない」設計が偵察の手がかりを減らします。
- 機微文書のインデックス範囲を最小化する:そもそも埋め込み化してRAGに載せる文書を必要最小限にすることが、万一の復元系攻撃に対する最大の緩和になります。
- ベンダーに構成と対策を確認する:SaaSのRAGを使っているなら、埋め込みモデルの取り扱いや異常クエリの検知について、提供元の方針を確認しておくと安心材料になります。
AI/LLMを業務に組み込む際の全体的な考え方は、公的機関のガイドも参考になります。まずはIPAの中小企業の情報セキュリティ対策ガイドラインで、外部サービス利用時の基本的な勘所を押さえたうえで、AI特有のリスクを上乗せして考えると整理しやすいでしょう。地道な話ですが、利用者への「機微情報を不用意にAIへ入力しない」啓発も引き続き重要です。
この研究の限界・留意点
過度に恐れないために、限界も明示しておきます。
- 査読前のプレプリントである点。手法の再現性や適用範囲は今後の検証を待つ必要があります。
- 攻撃には「候補となる既知モデルの集合」が必要です。世の中の任意のモデルをゼロから当てるわけではなく、候補群からの絞り込みである点は前提として押さえておきましょう。
- モデルの特定が、そのまま情報漏えいを意味するわけではありません。あくまで後続の攻撃を容易にしうる「偵察」段階の話です。
まとめ
- 埋め込み推論攻撃(EIA)は、返ってきた文書だけを観察して裏の埋め込みモデルを外部から特定する、という査読前の研究成果。
- 単独の被害は限定的だが、埋め込み反転など後続攻撃の足がかり(偵察)になりうる点に注意。リランカーがあっても一部有効とされる。
- 実務では、外部公開RAGの入出力管理・返す情報の最小化・インデックス範囲の絞り込みが現実的な緩和策。査読前研究として結果の一般化は慎重に。
出典
- Cedric Fitiavana Raelijohn, Sébastien Gambs, Jean-Francois Rajotte, “Embedding Inference Attack,” arXiv:2607.01276(2026年7月1日、査読前プレプリント)https://arxiv.org/abs/2607.01276
- IPA「中小企業の情報セキュリティ対策ガイドライン」https://www.ipa.go.jp/security/guide/sme/index.html