社内でLLM(大規模言語モデル)を使ったエージェント(メール処理やファイル操作などのツールを自律的に呼び出すAI)の導入を検討する情シスにとって、最大の不安がプロンプトインジェクションです。今回は、その対策の有効性を「攻撃者の立場」から検証した査読前の研究論文を、実務目線で読み解きます。結論を先に言うと、モデルの外側でルールを強制する『アウトオブバンド防御』は、従来のモデル内対策より攻撃者にとって突破しにくい可能性がある――ただしまだ小規模な検証段階、という内容です。
この記事でわかること
- プロンプトインジェクション、特に「間接的」な攻撃がなぜエージェントで怖いのか
- 「アウトオブバンド(モデル外)防御」とは何か、従来手法と何が違うのか
- 今回の査読前論文が示したこと/まだ言えないこと
- 情シスがAIエージェント導入時に押さえるべき勘所
そもそもプロンプトインジェクションとは
プロンプトインジェクションとは、攻撃者が用意した文章をAIに読み込ませ、本来の指示を乗っ取って意図しない動作をさせる攻撃です。OWASPの「OWASP Top 10 for LLM Applications」では、これが LLM01(最重要リスク)に位置づけられています。
特に厄介なのが間接的プロンプトインジェクションです。攻撃者がAIに直接打ち込むのではなく、AIが処理する外部コンテンツ――Webページ、PDF、メール本文、社内ドキュメントなど――に悪意ある指示を仕込んでおく手口です。エージェントは「外部のデータを読み、ツールを実行する」ことが仕事なので、汚染されたデータを1つ踏むだけで、ファイル送信や権限のあるAPI呼び出しを乗っ取られかねません。Anthropicは2026年2月のシステムカードで直接インジェクションの指標を取り下げ、企業にとっては間接インジェクションこそ本丸だと位置づけています。
「モデル内」防御の限界と「アウトオブバンド」という発想
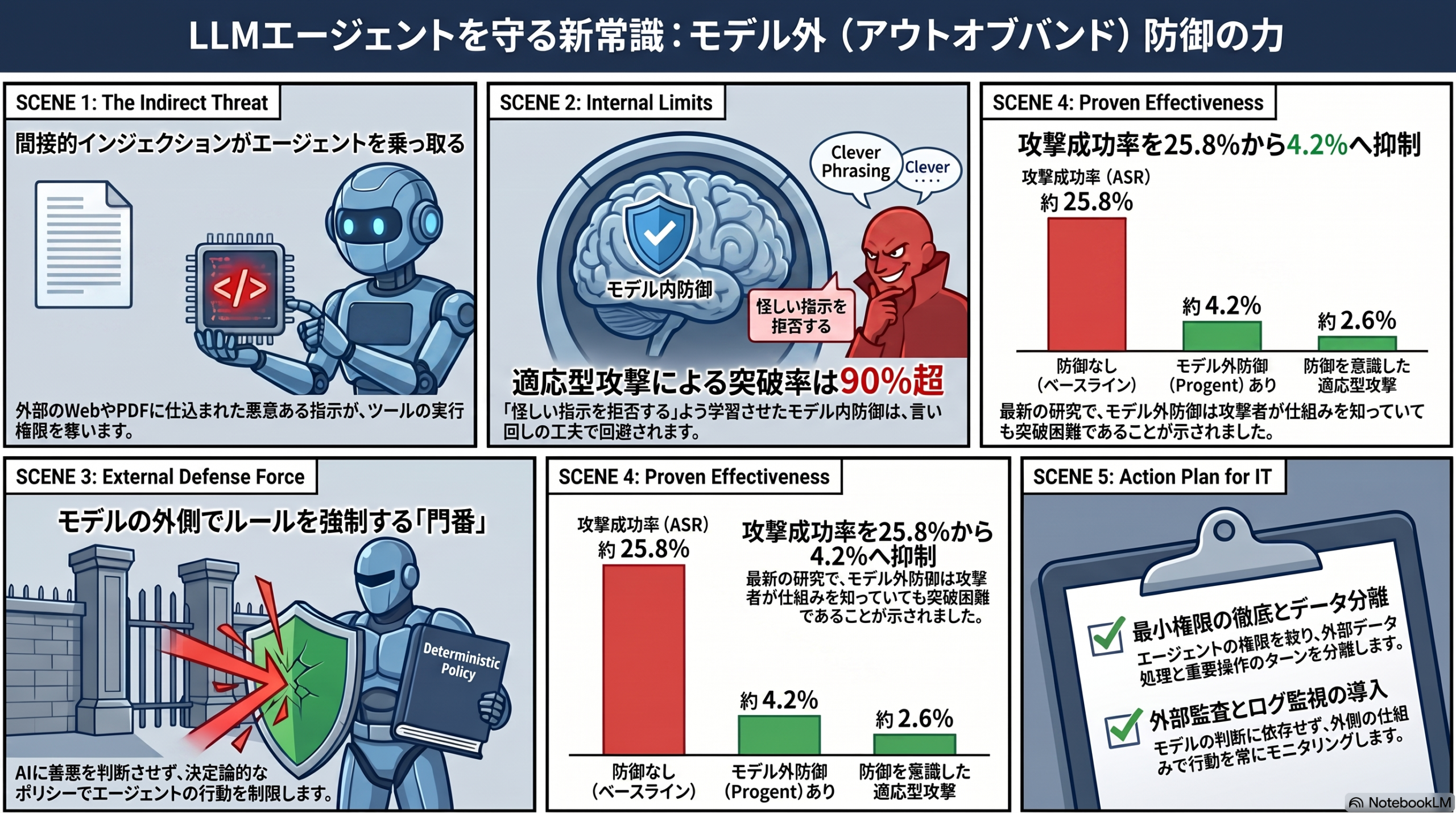
従来の対策の多くは、モデル自身に「怪しい指示は拒否しなさい」と学習・調整させるモデル内(in-band)防御でした。しかしこのアプローチは、攻撃者が防御の中身を知ったうえで設計する適応型攻撃(defense-aware attack)に弱いことが分かってきています。先行研究(arXiv:2503.00061)では、こうした適応型攻撃が12種類のモデル内防御を90%超の成功率で突破したと報告されました。一度学習させた「拒否」のクセは、言い回しを変えられると回避されてしまうわけです。
そこで注目されているのがアウトオブバンド(モデル外)防御です。モデルに善悪を判断させるのではなく、モデルの外側に決定論的(ルールベース)なポリシーを置き、エージェントの行動そのものを仲介・制限する考え方です。代表的な研究システムとして、論文では CaMeL、FIDES、Progent、RTBAS、FORGE の5つが挙げられています。たとえばGoogle DeepMindのCaMeLは、信頼できる指示と汚染されうるデータの流れを分離し(Dual LLMパターン)、権限のあるLLMが汚染トークンに直接触れないように設計されています。
今回の査読前論文が検証したこと
論文「Adaptive Evaluation of Out-of-Band Defenses Against Prompt Injection in LLM Agents」(arXiv:2606.26479、2026年6月25日投稿、Narisetty ら)は、こう問題提起します。「これらモデル外防御は、いずれも静的なベンチマークでしか検証されていない。モデル内防御がそうだったように、適応型攻撃の前では崩れるのではないか?」
そこで著者らは、エージェント評価環境 AgentDojo(メール処理やネットバンキング操作など97タスク・629のセキュリティテストを含む)を使い、オープンウェイトの小型モデル Qwen2.5-7B 上で、モデル外防御の一つ Progent に対し、ブラックボックス攻撃と手作りの適応型攻撃を3回ずつ仕掛けました。結果は次の通りです。
| 条件 | 攻撃成功率(ASR) |
|---|---|
| 防御なし(ベースライン) | 約25.8% |
| Progent(モデル外防御)あり | 約4.2% |
| 防御を意識した手作り適応型攻撃 | 約2.6% |
注目点は、防御の中身を知ったうえで作った適応型攻撃でも成功率が大きく上がらなかったことです。モデル内防御が適応型攻撃で90%超まで破られたのとは対照的に、モデル外でルールを強制する方式は、適応型攻撃者にとっても「より硬い標的」になりうる――というのが本論文の示唆です。
ただし、ここまでは言えないという限界
重要なのは、著者ら自身が結果を控えめに評価している点です。論文は今回の検証を「弱いモデル上での、単一のブラックボックス攻撃テンプレートによる、小規模な1データ点に過ぎない」と明言しています。より強力に最適化された攻撃や、他のモデル外防御(CaMeL等)での検証は今後の課題として残されています。
そもそもこれは査読前(プレプリント)の研究であり、結果は今後変わりうる前提で読む必要があります。「モデル外防御なら安全」と一般化するのは早計です。あくまで「有望な方向性を、攻撃者目線で1つ確認した」段階と捉えるのが妥当でしょう。
現場目線での受け止め
個人的な実感として、この研究の本当の価値は数字そのものより「評価のやり方」を問い直した点にあると感じます。ベンダーやOSSが「○%の攻撃を防ぎました」と静的ベンチマークの数値を掲げても、攻撃者は防御を知ったうえで攻めてきます。導入を検討する情シスとしては、提示された防御率を鵜呑みにせず「その数字は適応型攻撃を想定したものか?」を一段深く問う癖をつけたいところです。
同時に、「モデルにお行儀よく拒否させる」発想だけに頼るのは危うい、というメッセージも実務的です。AIに性善説で判断を委ねるのではなく、外側の仕組みで権限と行動を縛る――この設計思想は、ゼロトラストや最小権限といった従来のセキュリティ原則とまっすぐつながっています。新しい技術ほど、地に足のついた基本原則が効いてくるのは皮肉でもあり、安心材料でもあります。
情シスはどう備えるべきか
AIエージェント特有の対策を一から作り込む前に、まず公的機関の整理された指針を土台にするのが近道です。プロンプトインジェクションを含むLLMリスク全体像は OWASP Gen AI Security Project(LLM01: Prompt Injection) がよくまとまっています。組織としてのセキュリティ運用の底上げには IPA「中小企業の情報セキュリティ対策ガイドライン」 も併せて参照してください。
そのうえで、本研究やOWASPの議論から実務に落とせる勘所は次の通りです。
- 最小権限を徹底する:エージェントに与えるツール・APIの権限を必要最小限に絞る。乗っ取られても被害を限定できる設計に。
- 「外部データを読んだ直後に高リスク操作をさせない」:信頼できない入力を処理するターンと、送信・削除など強い権限を行使するターンを分離する。
- モデル外の制御を重視する:モデルの判断力だけに頼らず、外側のポリシーで行動を仲介・監査できる構成を検討する。
- 監視と検知を併設する:意図しないデータ持ち出しを検知できるよう、エージェントの行動ログを残す。
技術的な防御と並行して、利用部門への啓発も欠かせません。「外部から取り込んだ文章には命令が仕込まれていることがある」という前提を、AI利用者全員に共有しておくことが、地味ですが効きます。
まとめ
- 間接的プロンプトインジェクションはLLMエージェント最大の脅威(OWASP LLM01)であり、モデルに拒否を学習させる「モデル内防御」は適応型攻撃に弱いことが先行研究で示されている。
- 今回の査読前論文は、モデル外(アウトオブバンド)防御のProgentが、適応型攻撃に対しても攻撃成功率を低く保てた可能性を示した。ただし弱いモデル・単一攻撃での小規模検証であり、一般化はできない。
- 情シスは防御率の数字を「適応型攻撃込みか」で吟味しつつ、最小権限・権限とデータ取得の分離・行動の外部監査という基本原則でAIエージェントを縛るのが現実解。
出典
- Praneeth Narisetty ほか「Adaptive Evaluation of Out-of-Band Defenses Against Prompt Injection in LLM Agents」arXiv:2606.26479(2026年6月25日投稿、査読前) https://arxiv.org/abs/2606.26479
- 適応型攻撃が従来防御を突破した先行研究:arXiv:2503.00061 https://arxiv.org/pdf/2503.00061
- 評価環境 AgentDojo:arXiv:2406.13352 https://arxiv.org/abs/2406.13352
- OWASP Gen AI Security Project(LLM01: Prompt Injection) https://genai.owasp.org/llmrisk/llm01-prompt-injection/
- IPA「中小企業の情報セキュリティ対策ガイドライン」 https://www.ipa.go.jp/security/guide/sme/index.html